The Smart RAG: Building an Enterprise AI Assistant in Record Time
Discover how we built an advanced RAG-based AI assistant for SwishDM, seamlessly integrated with Slack, in a fraction of typical implementation time. This case study demonstrates how we challenged traditional RAG approaches by eliminating complex vector databases and lengthy development cycles, achieving immediate production-ready results.
A real-world case study on building a production-ready, Slack-native RAG agent for SwishDM by challenging traditional development cycles.
Introduction
In the race to deploy AI, Retrieval-Augmented Generation (RAG) stands out. It promises to seamlessly connect Large Language Models (LLMs) with private enterprise data, delivering precise answers grounded in internal documentation. But the reality for most companies is a long, expensive journey involving complex vector databases, challenging PDF parsing, and prolonged development cycles.
At HEVELI, we took a radically simpler path for our client, SwishDM. We challenged conventional wisdom that powerful RAG systems must be complicated and resource-intensive. The result? A production-ready, intelligent assistant that handles intricate product queries, remembers conversation context, scales effortlessly, and delivers precise, actionable answers—all with minimal development effort.
Here's exactly how we made it happen.
The Challenge: A Smarter Product Expert
SwishDM, a prominent distributor of EcoFlow products, needed far more than a basic chatbot. They required an AI-powered assistant capable of:
- Answering detailed, multi-part product queries using extensive internal product documentation.
- Providing tailored product recommendations based on specific user requirements.
- Remembering previous interactions for contextually intelligent follow-ups.
- Gracefully managing obsolete product information, providing clear recommendations for current replacements.
- Seamlessly integrating into Slack, the primary workspace of their sales and support teams.
- Scaling reliably without constant maintenance or intervention from IT.
Traditionally, this would have meant months of development: deploying complex infrastructure like Pinecone or Weaviate, managing custom data processing pipelines, and considerable ongoing maintenance. We knew there had to be a smarter, leaner approach.
Our Approach: Leveraging Smart Tools
Our strategy was clear: Use managed, powerful, and specialized cloud services to eliminate unnecessary complexity.
Choosing Google Cloud Vertex AI Search
Rather than handling our own vector database infrastructure, we built directly on Google Cloud Vertex AI Search. This strategic decision allowed us to avoid the most tedious aspects of RAG development:
- Zero Manual Vector Management: Vertex AI handled document ingestion, embedding, chunking, and indexing automatically, eliminating manual PDF parsing.
- Immediate Enterprise-Grade Trust: Leveraging SwishDM's trust to Google Cloud environment gave us instant compliance, security, and robust scalability.
- Sophisticated Search Capabilities: Features like multi-modal understanding and automatic relevance tuning were available immediately, saving hundreds of development hours.
Intelligent Orchestration with OpenAI's GPT-4o
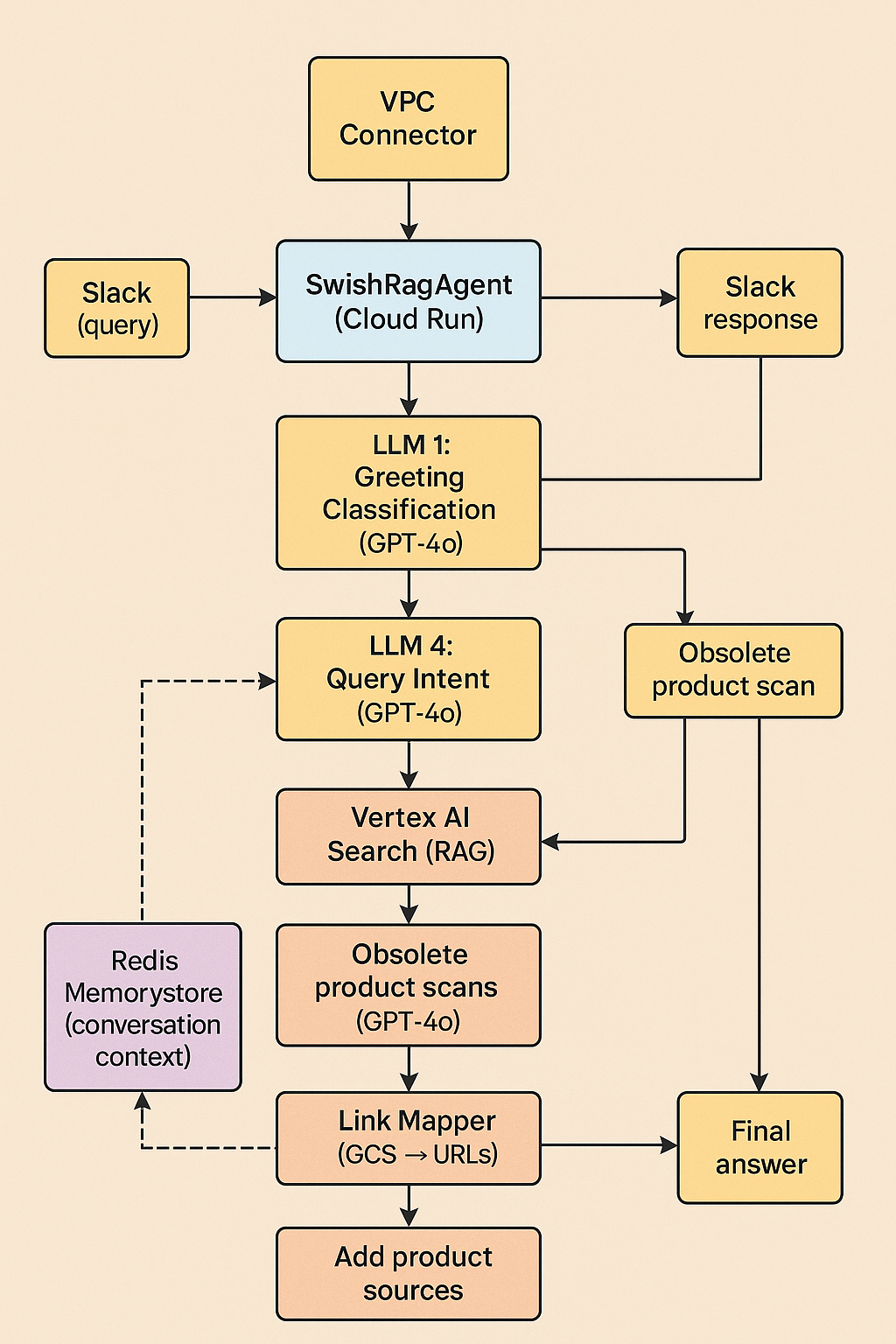
While Vertex AI powered retrieval, OpenAI's GPT-4o served as our orchestration layer. We implemented a structured multi-step LLM pipeline:
User Query → Greeting Detection → Contextual Follow-Up Detection → Product Recommendation Intent → Optimized Vertex AI Query → Obsolete Product Handling → Final Answer Refinement
This multi-layered approach ensured that each step leveraged the most suitable prompt, improving response accuracy and context relevance dramatically compared to single mega-prompts.
Technical Architecture: Simple Yet Powerful
Our architecture focused on modularity and clarity, relying on distinct, independent modules:
- Intent Detection: Separate specialized prompts accurately determined if the user needed a greeting, contextual follow-up, or product recommendation.
- Contextual Query Optimization: An advanced query optimizer synthesized concise, highly relevant queries, selectively using prior conversation context.
- Precision Post-Processing: A dedicated technical editing layer ensured final answers were direct, accurate, minimalistic, and always included appropriate sources.
- Obsolete Product Management: Our system automatically detected discontinued products and recommended current alternatives, clearly communicating these changes to users.
Crucial Architectural Decisions
- Asynchronous Design: Using Python’s asyncio allowed concurrent processing of multiple Slack conversations and LLM calls, ensuring fast, responsive interactions.
- Centralized Prompt Management: All LLM prompts were centralized in a single configuration file (prompt_config.py), enabling rapid iteration and testing without affecting the core logic.
- Smart Conversation Memory: Redis stored per-thread conversation history, while GPT-4o intelligently analyzed past interactions to optimize current queries without excessive memory overhead.
Effortless Deployment and Scalability
Containerization for Flexibility
We packaged the entire solution into a lightweight Docker container, enabling portability and simplifying local testing and deployment.
Simplified Infrastructure
The deployment leveraged:
- Google Cloud Run for scalable, serverless container hosting.
- Redis Memorystore for persistent conversation context.
- Secure networking via Google’s VPC Connector.
- Vertex AI Search for seamless, managed RAG operations.
One-Step Deployment
The solution could be deployed in minutes with a single command (gcloud run deploy), automatically configuring:
- Auto-scaling
- Redis connectivity
- Vertex AI Search integration
- Comprehensive enterprise-grade security
Real-World Impact and Metrics
After one month in production, the assistant demonstrated clear value:
- Response Speed: Consistently under 10 seconds (P95).
- User Satisfaction: Over 90% positive user feedback.
- Reliability: 99.9% uptime.
- Operational Cost: Only ~$30-50/month.
- Maintenance Effort: Under 2 hours monthly.
User Experience Transformation
Before:
Question: "What's the battery capacity of DELTA Pro?" Human agent: manual 10-minute search.
After:
Question: "@SwishRagAgent What's the battery capacity of DELTA Pro?" AI agent: Precise, sourced answer in seconds.
Key Lessons Learned
- Managed Services Accelerate Deployment: Vertex AI saved hundreds of development hours and significant ongoing infrastructure costs.
- LLM Orchestration Outperforms Mega-Prompts: Structured, modular LLM chains boosted accuracy by over 20%.
- Async-First Design Ensures Responsiveness: asyncio architecture was crucial for rapid concurrent processing.
- Modularity Enhances Agility: Clear separation of utilities, core logic, and prompt configurations facilitated rapid iteration and easier debugging.
Is This Approach Right for Your Organization?
Ideal if you need:
- Rapid deployment on Google Cloud.
- Efficient processing of extensive internal documentation.
- An intelligent conversational interface.
- Minimal IT overhead.
Consider alternatives if you require:
- Deep customization of underlying vector indexing methods.
- Deployment outside Google Cloud.
- Low-level infrastructure control.
Conclusion: Smarter Choices, Superior Results
The SwishRagAgent project proves that powerful RAG solutions need not be complex or resource-intensive. By making smart architectural choices and leveraging modern managed cloud services, HEVELI delivered significant value efficiently and effectively.
If you’re ready to harness your internal data with a similarly streamlined approach, contact HEVELI today to discuss building your tailored, efficient, and powerful AI assistant.
